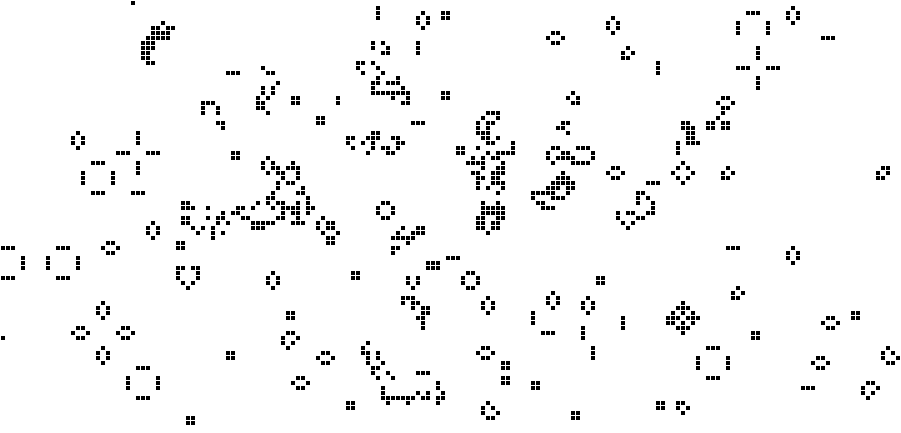When the guys in the picture above first learned chess, there weren’t that many tools for the job. In fact, books might have been the only significant self-study resource. The cool thing about learning chess in 2020 is that there are many different online study tools. Perhaps too many to choose from. So in this post I’ll be giving you a briefing and my personal recommendations.
Tactics training
There are three main platforms which people use for this category — Chess.com, Lichess and ChessTempo. From these three, despite the crappy-looking interface, most serious players swear by ChessTempo’s range of features. The website has both timed and non-timed tactical puzzles at different levels of difficulty, all taken from master games and tagged by their themes and rating level. Lichess and Chess.com on the other hand both seem to lack one half of the magical formula, with Chess.com being focused on timed tactics, while Lichess only has non-timed ones. Chess.com has the larger feature set of the two, but it’s also hidden behind their membership paywall, while ChessTempo seems to have the best of both worlds.
So the verdict for this section is fairly clear — ChessTempo is free and currently the best option.
Opening preparation
For studying openings, the most promising tool seems to be Chessable. It’s an online implementation of the spaced repetition learning approach and is in my experience the handiest way of memorising long opening variations and the ideas behind them. Some people have criticisms of the tool, but in my opinion those are mostly solved through correct usage. There are several anti-patterns which must be avoided:
Mindless Memorisation Chessable users may be tempted to record long book lines in their personal repertoires without any explanation behind the moves and then using the spaced repetition feature to mindlessly memorise them.
Excessive Variation Depth When buying pre-made courses especially, new players may get stuck into learning and memorising very long lines of theory which never occur in their games, while the shorter and more common traps and deviations are ignored.
In an attempt to solve both problems, I will make a recommendation about how you should be using Chessable. In my opinion, one should create two custom courses — a White Repertoire and a Black Repertoire. These can initially start off as simple reminders of your usual responses to each of the opponent’s first few moves. As you advance in your study of opening theory you should slowly expand this repertoire to include interesting lines and responses from your games, videos or books, but each move should always include a detailed explanation and never be there just for rote memorisation. This doesn’t preclude you from purchasing courses from the Chessable store, but I suggest only using those to initially learn the lines and then moving them over manually to your own custom repertoire courses, as this will allow you to add more explanation of the moves when needed or reduce the length of some lines where necessary.
My approach also has the great side-benefit of using Chessable in such a way that the free membership is completely sufficient. Cheapskates rejoice!
Endgame practice
With endgames being the section I personally most struggle with, there seems to be a frustrating lack of free endgame drills tools. ChessTempo’s endgame training works in the same way as their tactics, but is inexplicably restricted to 2 puzzles per day. Although accompanied by great explanations, Chess.com only has a limited set of endgame drills with no rating system. Lichess has a similar deal going on as Chess.com, except fewer puzzles. Aside from biting the bullet and getting a ChessTempo membership, manually setting up a random engame from a book into Lichess’ board editor and playing against Stockfish might be the second best option.
Recommendation: Start with Lichess’ or Chess.com’s (if you have the membership) endgame practice puzzles to get the basic mating patterns down. Perhaps use this neat open-source tool to practice a bunch of endgame tablebase positions. Somewhere during this process pick up a book on more advanced endgame ideas such as Silman’s Complete Endgame Course (my personal favourite) and proceed either drilling random endgames using ChessTempo’s endgame problems or by manually grabbing them from books / websites and playing against Stockfish on Lichess.
Actually playing the game
This one comes down much more to personal preference than the other categories. Lichess and Chess.com are the big two, but alternatives such as Chess24 and ICC exist. Lichess is completely free to use and also open-source, which is a big plus for me as a software engineer. On the other hand, Chess.com’s premium membership does give you access to a few extra cool features such as their library of videos. I personally like the cleaner interface of Lichess and have had a better experience with the userbase. Chess.com has a larger US-centric userbase, which in my personal experience includes a few extra toxic assholes. Perhaps it’s my luck, but playing in club-organised classical tournaments on Lichess I’ve never had to deal with the same negativity I face pretty often in a Chess.com game chat.
Recommendation: Try both. Lichess is free and Chess.com has a free trial. Popularity is pretty up in the air, for example — Magnus Carlsen often plays on Lichess, while Hikaru Nakamura has a Chess.com sponsorship. I personally prefer Lichess’ interface and social features.
*One thing to note is the rating difference between the two platforms. There is a different algorithm and starting rating used for both websites, so your rating will tend to be around 200-400 points higher on Lichess. For a detailed analysis of how both compare against eachother and FIDE, check out this study.
Extra Stuff
If you’ve ever explored chess openings, you will have come across 365chess’ openings explorer. It’s a handy tool which can give you the stats to a limited depth, but worth pointing out that Lichess’ free opening explorer has the same exact dataset with no such restrictions.
I am going to go over what I consider to be the most crucial factor which differentiates chess from other sports / games and how this can help us prioritise and focus our study — blunders.
Building a house of cards
Chess is a game in which the superior player can play 45 amazing moves in a row against someone who moves randomly and STILL loose from a single oversight near the end. Unlike any other sport where a big winning advantage against an inferior player is impossible to throw, in chess the whole effort can be undermined by a single mental slip, analogous to the construction of one of these:
Although most players recognise this fact, few of them completely internalise and integrate it with their approach to chess. So let’s examine the consequences of this:
Most non-master games are decided by blunders Under this umbrella we can put games rated under 2000 or so, in which at least half are decided through simple tactical oversights. Therefore, to attain the most rapid improvement at these levels, one must develop a method of thinking which is focused on eliminating blunders. This means thinking about your opponent’s moves more than your own.
To win against weak players, one must be able to punish blunders It’s not enough to eliminate blunders from one’s own play, it is also essential to notice and be able to punish the opponent’s blunders as well.
Subtle positional play can only be relevant in the absence of blunders Strategic considerations which may or may not improve one’s position by a few centipawns will be comparatively irrelevant in games which contain swings of +/-5. This means that most time spent on studying subtle positional play is ineffective for non-master players.
In non-master games there are no positions which are truly lost Many players get frustrated after making a mistake and either start playing on autopilot or simply resign. For lower-rated games especially, this can lead to a huge number of missed opportunities. Even a lone king defending against an army will often be able to squeeze out a stalemate due to an opponent’s oversight.
Especially in players coming from other less-unforgiving strategy games there can be a trap one falls into of over-thinking the trade-offs between a few decent candidate moves. This can sometimes be a reason new players fall into time pressure. The essential lesson to learn here is that 30 decent moves will almost always beat 29 excellent moves and 1 blunder. The majority of calculation time should be spent on trying to refute the move you are about to play. Do your best to find any possible way you could be punished and if you can’t, simply play the move.
Hopefully this has explained my thoughts behind putting such a focus on the tactical training / practice elements of chess study in my plan.
Thank you for reading and I hope you got something out of it!
This post is going to be the first of a series related to a new task I will be undertaking — to implement a structured chess study plan with the aim of attaining reasonable expertise and eventually participating in live over-the-board rated tournaments. In this first instalment, I will be going over my findings and thoughts on the general structure of a chess study plan and the decisions I have made. This would serve a dual purpose:
Solidifying my goals Holding yourself accountable is a great way to increase motivation with difficult endeavours such as the study of chess. Additionally, verbalising ideas forces one to hold them to a higher objective standard, which should be helpful with preventing pitfalls and circular traps in thinking.
Providing a summary to other self-students There are plenty of conflicting and confusing opinions on the internet about chess study methods and I have spent a lot of time trying to discern the good ideas from the less helpful ones and even though I don’t have the credentials to back my opinions up, I can at least try to provide the reasoning for my choices.
The three-pronged approach
The way I have started to break down chess study initially is inspired by this video by IM Kostya Kavutskiy, in which he lays down a three-part base:
Playing This is the most obvious element of chess study, but according to most coaches / professional players it might actually be the least impactful. There are two main reasons for this. Firstly, examining your thinking on a meta-cognitive level during a game is difficult and better done afterwards when you can extract more value by analysing when and how you went wrong in your thinking process. Secondly, learning new ideas during play is not going to happen unless you randomly stumble upon a tactical / strategic pattern and you’re not going to be seeing those patterns if you don’t learn them in the first place.
Studying This category includes reading books, watching videos, attending lectures and other similar activities. This would be the second-most-important of the three approaches, with the main goals here being to encounter new ideas and integrate them into your future games. The two main pitfalls to avoid in this approach are jumping too fast across different new ideas and overdoing the passive learning aspects. Both pitfalls lead to simply encountering many ideas and terms, but never properly integrating them into your games. This might make you seem smarter in chess conversations when you can pull out technical jargon such as minority attacks, IQP, Lucena position, Philidor position, but not actually understanding how to play in these situations.
Practice Drills Saving the best for last, this category includes mainly tactics and endgame puzzles, but also visualisation exercises, coordinates training and other fun stuff. Obligatory to any chess-related writings, I have to mention the Russians here with their practical philosophy of chess, which mainly considered the game as a kind of sport, rather than the intellectual endeavour, which it is though of as in the West. Many absolute beginners and non-chess-players will have the false belief that you must be some kind of genius to understand chess, but as you dive deeper into the game you quickly have your pre-conceived notions of intelligence shattered:
Chess is like a martial art. You learn some basic techniques, practice them thousands of times and eventually use them on your enemies to great effect.
Okay, well, at the highest levels of chess there is a lot more memorisation of computer lines and I’m oversimplifying here, but the basic lesson to be extracted is that for the most part, being better at chess is simply about practising the same basic elements everyone else is practising, but more. Magnus Carlsen doesn’t know any tricks for finding pins and forks which you don’t and he’s not inherently more talented, although he did start young and spent his whole life staring at chess boards looking for them, to the point where he can play dubious opening moves which are theoretically worse and still outplay every other GM in the middle/endgame.
Of course, none of us are going to become the next Magnus. This brings us to the next section:
Self-evaluation and setting realistic goals
Improving at chess is hard and takes a lot of time. Never has a more obvious statement been formulated. The older you are when you first encounter and start playing chess, the harder it is. This is partially due to neuroplasticity being higher in children. In short, learning is the literal process of changing your brain structure and this tends to be easier to do the earlier you start. This is why learning a foreign language is easiest to do by just being in a bilingual family and this is also why essentially all super strong chess players start at the ages of 3-10 years old.
But don’t be too discouraged as this is actually not the only factor in play here. Another big one is time. Kids have a lot more time to be hyper-focused on pointless activities such as chess (yes, chess is a mostly pointless activity, don’t attack me) and don’t have to be burdened with financial issues and real-life stress (lots of them come from wealthy families which can afford personal coaches and frequent travel). But for an adult with a career and/or family, time and energy ends up being another big bottleneck. So this is another reason to adopt a more structured approach if you want to maximise your time. You may never reach the desired GM title, but with some effort and perseverance you can systematically annihilate all of your friends and relatives and that’s all that really matter, doesn’t it.
So what does the learning curve tend to look like and what can be realistic goals? The learning rate tends to follow a similar power law to all other kinds of learning which is great news for players who want to simply get good enough to beat their friends, but also bad news for everyone who wants to get much better than that. When starting chess initially, one can gain hundreds of points in a month simply by practising some basic tactics.
Getting from ~0-1000 rating can take around a month with about 30-90 minutes of well-spent time per day. At this stage the majority of games are lost by hanging material in a single move on both sides and the player who makes the last blunder tends to loose.
Progressing ~1000-1600 you can expect around 200-300 rating points per year with similar commitment. At this stage, 2-3 move tactics mostly determine the games, along with some basic opening ideas / principles.
Progressing ~1600-2000 is where you will either eventually reach a plateau or slowly keep grinding up with 50-100 points per year. At this stage, 2-4 move tactics are still the bread and butter, but some theoretical opening lines and strategical ideas start coming into play.
Anything above 2000 rating is out of the scope of most normal people’s study goals and tends to involve very serious long-term commitment along with money spent on coaches, books, courses, travel, etc.
Summary and next steps
In summary, the game of chess is a sport like any other and improvement tends to consist of learning a new concept, practising it extensively and applying it during games. Reaching the upper echelons is a difficult and life-long endeavour. Realistic goals and effective study are important to maintain motivation.
This has only been a cursory view of the chess study process and as I said in the beginning, there will be a series of posts going over in detail each element of my study program and the reasoning behind it.
You can look forward to further exploration of schedule, details in the three approaches, my own self-evaluation, goals and tons and tons of recommendations for books and online resources.
Thank you for reading and I hope you got something out of it!
“Maria could almost see it: a vast lattice of computers, a seed of order in a sea of random noise, extending itself from moment to moment by sheer force of internal logic, “accreting” the necessary building blocks from the chaos of non-space-time by the very act of defining space and time.” (Egan, 1994)
1. Introduction
Cellular automata is a term referring to a type of discrete computational system, which was first discovered by the Hungarian-American mathematician John von Neumann (1951), but gained wider popularity outside academia in the 1970’s with John Conway’s Game of Life (Gardner, 1970). Cellular automata vary widely in their properties, but can be categorised by the common feature of being “comprised of a number of discrete elements called cells”, where “each cell encapsulates some portion of the state of the system” (Yuen and Kay, 2009). Typically, these cells are positioned uniformly in a grid and governed by spatially localised update rules, dependant on the state of neighbouring cells. Most automata systems represent time discreetly by handling cell updates simultaneously, resulting in a series of “generations” or “steps”.
2. Elementary Cellular Automata
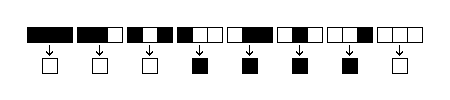
The simplest non-trivial example of a CA system is Stephen Wolfram’s elementary cellular automata, which consists of a 1-dimensional grid of cells, each carrying a binary value of either 1 or 0 and a universal update rule, which takes into account the states of the two immediately neighbouring cells in the previous generation and either retains or changes the state of the cell in the next generation (1982). With 1-dimensional cell grids, each ruleset can be easily explicitly illustrated, as shown in figure 1.
Figure 1: Visual representation of a ruleset for an elementary cellular automaton
These rulesets are also often described by the decimal representation of the binary number, which is formed by listing the possible outputs of the ruleset. The ruleset in figure 1 would be represented in binary as 00011110 and in decimal as rule 30.
2.1. Classes of ECA
Stephen Wolfram, in his paper “Universality and Complexity in Cellular Automata”, further analyses ECA’s and categorizes them into four types (1984):
Class 1: Convergence to uniformity (See figure 2)
Class 2: Convergence to repetition or stability (See figure 3)
Class 3: Randomness (See figure 4)
Class 4: Complexity (See figure 5)
Automata of class 1, 2 and 3 have interesting properties, such as high sensitivity to initial conditions, pseudo-random generation with simple non-random initial conditions and fractal pattern generation (See figure 6). Wolfram conjectured that class 4 systems are capable of universal computation, which was later proved by Matthew Cook (1984; 2004).
Figure 2: Class 1 cellular automata - uniformity
Figure 3: Class 2 cellular automata - repetition
Figure 4: Class 3 cellular automata - randomness
Figure 5: Class 4 cellular automata - complexity
Figure 6: ECA rule 26 generating a series of Sierpinski Triangle fractals
Moving away from the simplest case of ECA, there exist many possible CA, varying in number of dimensions, neighbourhood size, number of possible states, continuous states, non-rectangular grids, non-deterministic update rules, etc.
3.1. Conway’s Life
Perhaps the most famous and deeply studied two-dimensional CA is John Conway’s Life, which was created by the British mathematician through experimentation, with the goal of creating an unpredictable and interesting CA, which would exhibit life-like behaviour (See figure 7). This ruleset was later proved to be turing-complete (Rendell, 2016).
Figure 7: 300th generation of Conway’s Life, starting with a random initial configuration
Another fascinating cellular automata, which is particularly well-suited to expressing and modeling logic gates is “wireworld”. It was originally invented by Brian Silverman in 1987 (Dewdney, 1990). The cells in wireworld take one of 4 different states: empty, electron head, electron tail or conductor and update in a Moore neighbourhood with the following rules:
empty -> empty
electron head -> electron tail
electron tail - conductor
conductor -> electron head (if one or two of the neighbouring cells are electron heads, otherwise remain conductor)
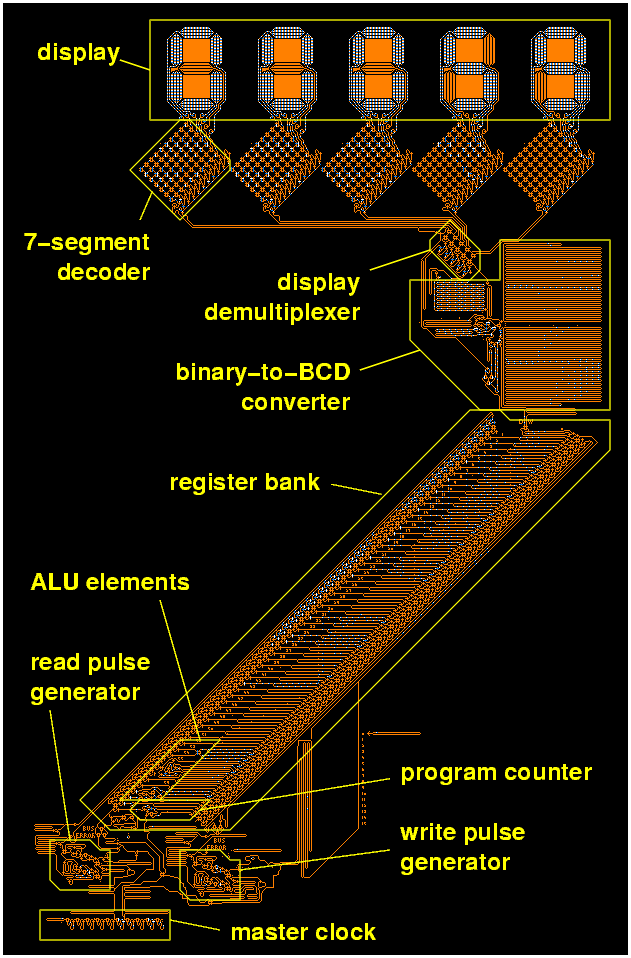
Being turing complete, wireworld allows for the construction of any electronic logic circuit, with Mark Owen and David Moore going as far as building a full wireworld programmable computer, including five 7-segment digit displays (See figure 8) (2004).
Figure 8: Moore and Owen’s wireworld computer (2004)
4. Applications of Cellular Automata
There exist many possible applications of CA, such as musical composition, structural design, modeling fluid dynamics, modeling seismic wave propagation, digital mechanics, etc. Localisation of update rules for CA models allow for high parallelisation of computation, making CA simulations highly efficient (Spezzano and Talia, 1999). This section will outline two examples: road traffic modeling and procedural content generation for games.
4.1. Road Traffic Modeling
Similar to wireworld’s modeling of electron movements, CA have been used to model road traffic. The simplest deterministic model used is Wolfram’s rule 184 ECA to model unidirectional single-lane traffic. This model is rather limiting, since “there are only two possible kinematic wave speeds, i.e., +1 and −1 cell/time step” and the model does not allow for non-homogeneous vehicles (Maerivoet and De Moor, 2005). Rule-184 models have been extended further to move past these limitations, with one example of this being the Fukui & Ishibashi model (FI), which allows for “cars advancing by multiple sites per one time step” (Fukui and Ishibashi, 1996). The field of CA road traffic modeling has kept evolving, with more complex models, such as Brake-light, being used to produce more and more accurate and useful predictions (Maerivoet and De Moor, 2005).
4.2. Procedural Content Generation
Another usage for cellular automata is procedural content generation (PCG) for games. This approach relies on the self-organization capabilities of CA and allows for the generation of natural-looking terrain. The approach, which is taken when generating two-dimensional content is this:
The map is initialised as an N*M grid of empty cells (floors).
Using a uniform distribution random number generator, some of the cells are changed to filled (walls).
A two-dimensional CA ruleset is applied for an X number of steps over the grid, which has the effect of reducing the random noise and forming larger cave-like structures.
Optionally, smaller caves are filled in using a flood-fill algorithm.
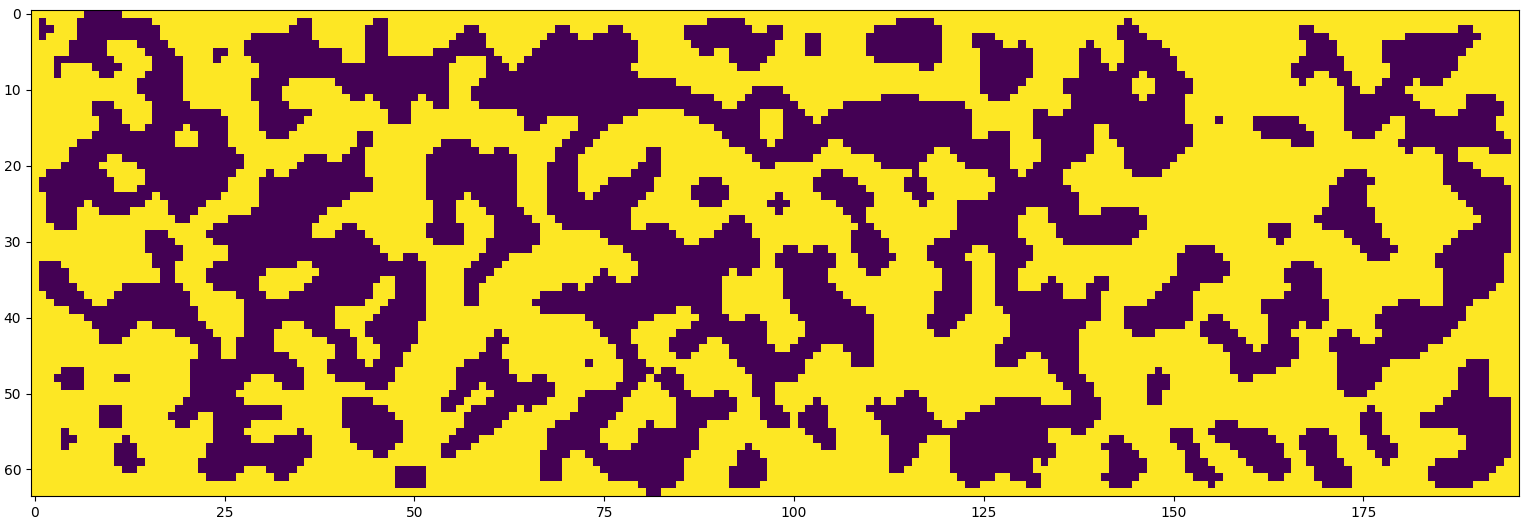
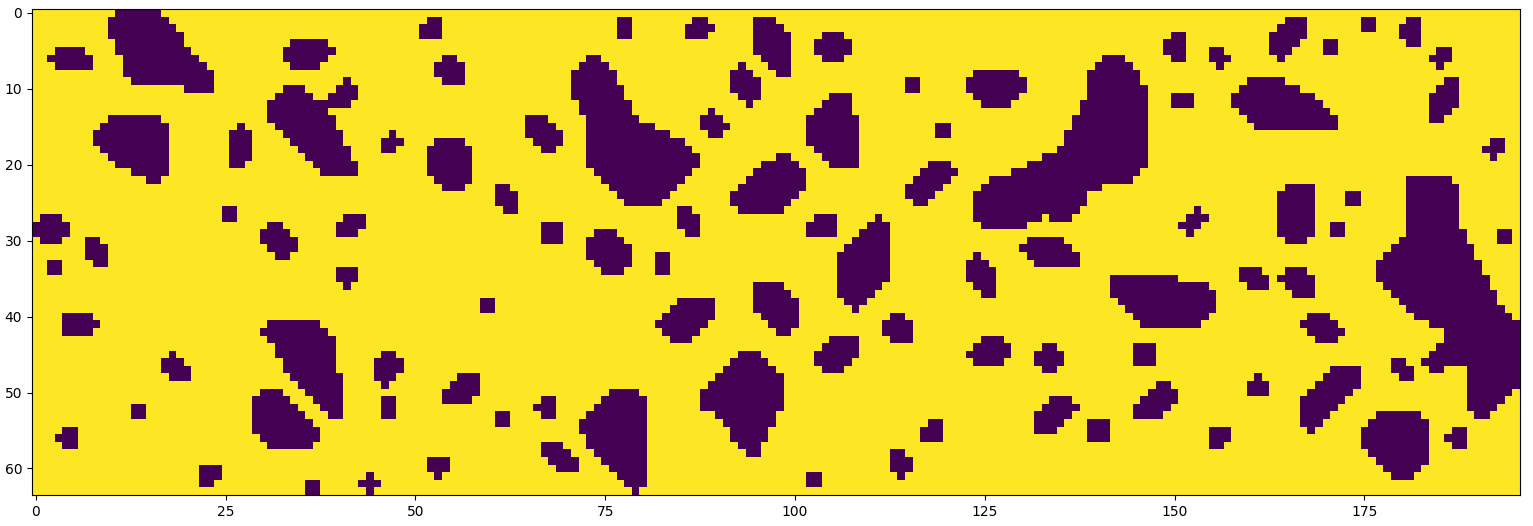
In two dimensions “the computational effort equals n(wh(2M + 1)^2), where w and h are the width and height of the grid, respectively, n is the number of CA iterations” and M is the Moore neighbourhood size, but the algorithm can be generalised for any number of dimensions by changing the neighbourhood type (Johnson,Yannakakis and Togelius, 2010). For an example of the resulting map, see figures 9.1 and 9.2.
Figure 9.1: Randomly generated cave map using CA
Figure 9.2: Randomly generated cave map using CA with a different ruleset
*I’ve published these examples and a python package for generating random 2D terrain right here.
5. Summary
Cellular automata have properties which make them viable for a variety of different applications, but are most well suited for simulating physical systems, due to the localisation of their update rule, which mimics the physical world. Cellular automata models are computationally efficient and allow for easy parallelisation. They have been used to successfully solve scientific and engineering problems in road traffic flow, fluid dynamics, cryptography, structural design, molecular biology, finance, etc. In road traffic modeling, elementary cellular automata simulations have been used to efficiently approximate single and multi-lane traffic flow, with some limitations caused by the simplicity and homogeneity of these systems. More complex cellular automata rulesets have been devised to handle these limitations, such as the Fukui & Ishibashi and Brake-light models. Cellular automata have also found a use in procedural content generation for games, due to their self-organization capabilities and computational practicality for creating natural-looking terrain.
6. References
Cook, M. (2004). Universality in Elementary Cellular Automata. Complex Systems, vol. 15 (1), pp. 1-40.
Dewdney, A. K. (1990). Computer Recreations. Scientific American, vol. 262, (1), pp 146-149.
Egan, G. (1994). Permutation City. Millennium Orion Publishing Group. London.
Fukui, M., & Ishibashi, Y. (1996). Traffic Flow in 1D Cellular Automaton Model Including Cars Moving with High Speed. Journal of the Physical Society of Japan, 65(6).
Gardner, M. (1970) . The fantastic combinations of John Conway’s new solitaire game “life”. Scientific American, 223, pp. 120-123.
Johnson, L.,Yannakakis, G. and Togelius, J. (2010). Cellular automata for real-time generation of infinite cave levels. DOI: 10.1145/1814256.1814266
Maerivoet, S. and De Moor, B. (2005). Cellular automata models of road traffic. Physics Reports vol. 419 pp. 1 — 64.
Rendell, P. (2016). Turing Machine in Conway Game of Life. In Designing Beauty: The Art of Cellular Automata pp. 149-154. Springer, Cham.
Spezzano, G. and Talia, D. (1999). Programming cellular automata algorithms on parallel computers. Future Generation Computer Systems. Volume 16, Issues 2–3. pp. 203-216.
von Neumann, J. (1951). The general and logical theory of automata. In L. A. Jeffress (Ed.), Cerebral mechanisms in behavior; the Hixon Symposium pp. 1-41. Oxford, England: Wiley.
Wolfram, S. (1982). Cellular automata as simple selforganizing systems. Caltech preprint. pp. CALT–68–938.
Wolfram, S. (1984). Universality and Complexity in Cellular Automata. Physica D: Nonlinear Phenomena 10, no. 1–2: pp. 1–35.
Coding Snake on the BBC micro:bit using MicroPython
In this post I’ll give a brief introduction to the BBC micro:bit and walk you through an implementation of the classic game Snake on the micro:bit’s retro-looking 5x5 display.
Why Snake?
Snake is a great fit for a “Hello, World” program for the micro:bit, since it can work on the small resolution display and we can make due with the two buttons on the board.
Why Python?
There are three main programming languages we can use with the micro:bit:
Blockly: a visual programming language, primarily targeted at children for educational purposes
Javascript: a multi-paradigm scripting language, mainly used on the client-side in web applications
Python: a multi-paradigm scripting language, designed for simplicity and code readibility
I’ve picked Python, because its syntax most-closely resembles human language and tends to be understandable, regardless of previous programming experience.
Oh, and also… well… Python is a snake, isn’t it?
Let’s get started!
One of the ways to code our micro:bit would be to write our program in the recommended text editor, press Download and upload the code using the provided micro USB cable to test it.
While this is a great way to start, when we get into more complex programs we may want an easier way to debug our code before compiling and uploading. Thankfully, Pete Dring from blog.withcode.uk has taken the time to create a browser-based Python IDE with a micro:bit simulator built-in.
There are only three things we need to do to get set-up:
Type in our import statement for the micro:bit library on the first line:
from microbit import *
Press the green run button to see our simulator pop-up:
Our Player
In the game of Snake, the player is represented by a line of pixels, which starts at length 1 and grows over the course of the game. The snake moves in a single direction constantly, until a button is pressed to change it. To represent the snake, we can simply create a list of tuples (points) for each pixel:
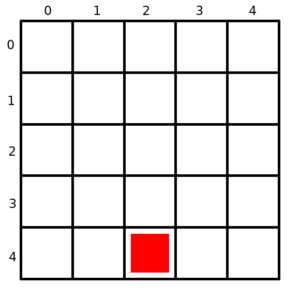
snake = [(2, 4)]
As you can see, I have initialised the snake at the coordinates of (2, 4). These coordinates will correspond with the coordinate system of the micro:bit itself, which looks like this:
For the direction, we can simply express it as a number from 0 to 3:
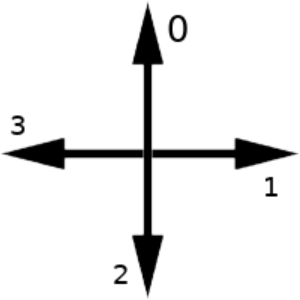
direction = 0
This is chosen arbitrarily, but in my case 0 represents movement in the direction of negative Y, 1 in the direction of positive X, 2 in positive Y and 3 in negative X, like so:
The other value we need to store is the player’s score, which is also just a simple integer, starting at 1:
score = 1
Food
The point of the game is to collect food and grow the snake. Our “food” will just be another pixel on the board, which starts at (1, 1). After it has been eaten, another piece of food will be randomly assigned coordinates.
food = (1,1)
Time
In my version of the game, when the player collects food, the speed of the snake increases. The way we are going to do this is by introducing a delay variable, which will start at 1000 milliseconds:
delay = 1000
The Game Loop
At the core of all games, there exists a game loop. It’s an infinite loop with three responsibilities:
Our control scheme is going to be quite simple: the left button will move the snake’s direction counter-clockwise, while the right button will move it clockwise.
In order to programmatically get the micro:bit’s button presses, we will use the functions button_a.get_presses() and button_b.get_presses(). What these do is return the number of times a button has been pressed since the last call of the function. Button A is micro:bit’s way of referring to the left button and button B to the right one.
Since our direction value needs to wrap around when we try to increase/decrease it past 3 or 0, respectively, our code will look like this:
direction = (direction + 4 - button_a.get_presses()) % 4
direction = (direction + button_b.get_presses()) % 4
As you can see, in the counter-clockwise direction we are essentially adding the “inverse” of the number. We can have this notion of inverse, because of the aforementioned property of our direction to wrap around.
Moving the Snake pt. 1
First of all, we will store the coordinates of the head of the snake in local variables for easier access:
x, y = snake[0]
The snake’s movement will be split into two parts. First one will be attaching a new “head” to the front of the snake in the direction of movement, while the second one will be removing the last segment from the snake. The reason for this split is because feeding the snake will make the second part unnecessary.
Here’s the code for direction 0:
if (direction == 0):
if (y != 0):
snake.insert(0, (x, y - 1))
else:
snake.insert(0, (x, 4))
If we haven’t reached the end of the display, we add a new head segment to the front, else we add it to the opposite side of the display. This is how we wrap around.
And here is the code mirrored to the other three directions:
The start delay, minimum delay and delay decrement amount can be adjusted according to preference.
To make the random.randrange() function work, we also need to import the random module at the start of our program:
from microbit import *
import random
Self-collision
The losing condition for the game will be a self-collision of the snake’s head with any other segment. This is accomplished with a simple for-loop:
for point in snake[1:]:
if (point == snake[0]):
running = False
If you are confused about the Python list slicing notation used (snake[1:]), here’s a stack overflow link.
Rendering
Displaying the game state each frame consists of clearing the screen, displaying each snake segment and displaying the food:
display.clear()
for point in snake:
display.set_pixel(point[0], point[1], 9)
display.set_pixel(food[0], food[1], 9)
The micro:bit functions we are using here are display.clear(), which is self-explanatory and display.set_pixel(), which takes as input an X coordinate, Y coordinate and a pixel intensity from 0-9. For simplicity, we are only using 9 to represent filled and 0 to represent empty.
Tick
And the last action of our game loop is to “tick” the in-game clock by pausing for the pre-set delay:
sleep(delay)
For those not familiar with game development, this is a practical simplification, since you may notice that our frame-rate is tied to the clock-speed of the CPU. For bigger and more hardware-intensive games, a concept called delta time is used.
Minimum Viable Product (MVP)
At this point, we have our first playable version of the game!
The current code in its entirety looks like this:
from microbit import *
import random
snake = [(2, 4)]
direction = 0
score = 1
food = (1,1)
delay = 1000
running = Truewhile running:
# Input
direction = (direction + 4 - button_a.get_presses()) % 4
direction = (direction + button_b.get_presses()) % 4# Update
x, y = snake[0]
if (direction == 0):
if (y != 0):
snake.insert(0, (x, y - 1))
else:
snake.insert(0, (x, 4))
elif (direction == 1):
if (x != 4):
snake.insert(0, (x + 1, y))
else:
snake.insert(0, (0, y))
elif (direction == 2):
if (y != 4):
snake.insert(0, (x, y + 1))
else:
snake.insert(0, (x, 0))
elif (direction == 3):
if (x != 0):
snake.insert(0, (x - 1, y))
else:
snake.insert(0, (4, y))
# Feeding Checkif (food == (x, y)):
score += 1
food = (random.randrange(5), random.randrange(5))
if (delay >= 500):
delay = delay - 50else:
snake.pop()
# Collision Checkfor point in snake[1:]:
if (point == snake[0]):
running = False# Render
display.clear()
for point in snake:
display.set_pixel(point[0], point[1], 9)
display.set_pixel(food[0], food[1], 9)
# Tick
sleep(delay)
We can test this version either by compiling using the “Download HEX” button on the right and sending it to our micro:bit using micro USB or just playing it right there in the browser with the green “Run” button.
Next Steps and Improvements
Currently, we are keeping track of the score, but have no way of displaying it to the player. We could possibly do this using either display.scroll() or display.show(), which help us put scrolling text or sequential characters on the screen.
Other improvements we could make might be adding an introductory message, replacing some of the magic numbers in our code with named constants or even using the micro:bit’s file system to store previous high-scores.
Here’s one of my “cosmetically enhanced” versions of the code - GitHub link.
And here’s a short video of me playing the game:
If you would like to learn more about the micro:bit or grab one for yourself or as a gift to a younger future programmer, visit the website.
Thank you for reading and I hope you got something out of this post!
The very first blog post, because one always needs to start somewhere.
Who am I?
My name’s Petar Peychev and I’m a Computer Science student at Nottingham Trent University and former Software Engineering student of SoftUni. I was born in a small fishing town called Tutrakan on the right bank of the Danube in Bulgaria.
Throughout my brief stay on this planet, I have been captivated by many seemingly unconnected ideas, gadgets and pursuits. My main activities revolve around the field of computer science, but I love exploration too much to exclusively specialise. Here’s a small subset of the things, which occupy my mind sometimes:
Learning by explaining One of the widely-known pieces of applied psychology is the fact that explaining something to others is a great way to learn. I intend to use this blog as an engine to drive my learning process, while simultaneously getting some content as a side effect.
Cultivating an online identity As having an online footprint is practically inevitable these days, especially for someone in my field, a personal blog is a tool one can use to curate their digital identity.
An outlet for miscellaneous thoughts With constantly getting distracted by new and exciting ideas, I often find myself struggling to find a place to store various thought nuggets. Tools, which have all served this purpose in my life before include Google Keep, physical journals, a frighteningly massive Google Docs file, and any friend who might listen. I hope to use the blog as another such outlet, where I can initially deposit ideas and eventually develop them into complete posts.
What kind of content can you expect?
My plan is to dedicate the majority of the content here towards computing-related topics, but still put out the occasional miscellaneous post. A rough balance, which I’ll strive towards is 80/20%. With my current obsession being programming languages and compilers/interpreters, related content will probably follow.
 Petar Peychev
Petar Peychev